
强化学习(RL)对大模子复杂推理身手训导揣测键作用,但其复杂的研究经过对考试和部署也带来了强大挑战。近日,字节逾越豆包大模子团队与香港大学合股建议 HybridFlow。这是一个机动高效的 RL/RLHF 框架,可显耀训导考试朦拢量,裁减设立和崇敬复杂度。实验收尾标明,HybridFlow 在多样模子规模和 RL 算法下,考试朦拢量比拟其他框架训导了 1.5 倍至 20 倍。 在大模子后考试(Post-Training)阶段引入 RL 措施,已成为训导模子质料和对皆东说念主类偏好的关键时代。关

强化学习(RL)对大模子复杂推理身手训导揣测键作用,但其复杂的研究经过对考试和部署也带来了强大挑战。近日,字节逾越豆包大模子团队与香港大学合股建议 HybridFlow。这是一个机动高效的 RL/RLHF 框架,可显耀训导考试朦拢量,裁减设立和崇敬复杂度。实验收尾标明,HybridFlow 在多样模子规模和 RL 算法下,考试朦拢量比拟其他框架训导了 1.5 倍至 20 倍。
在大模子后考试(Post-Training)阶段引入 RL 措施,已成为训导模子质料和对皆东说念主类偏好的关键时代。关联词,跟着模子规模的不休扩大,RL 算法在大模子考试中靠近着机动性和性能的双重挑战。传统的 RL/RLHF 系统在机动性和效果方面存在不及,难以相宜不休自满的新算法需求,无法充分推崇大模子后劲。
据豆包大模子团队先容,HybridFlow 采选夹杂编程模子,将单截至器的机动性与多截至器的高效性相兼并,解耦了截至流和研究流。基于 Ray 的散布式编程、动态研究图、异构诊疗身手,通过封装单模子的散布式研究、调和模子间的数据切分,以及援手异步 RL 截至流,HybridFlow 大约高效地终了和现实多样 RL 算法,复用研究模块和援手不同的模子部署姿色,大大训导了系统的机动性和设立效果。
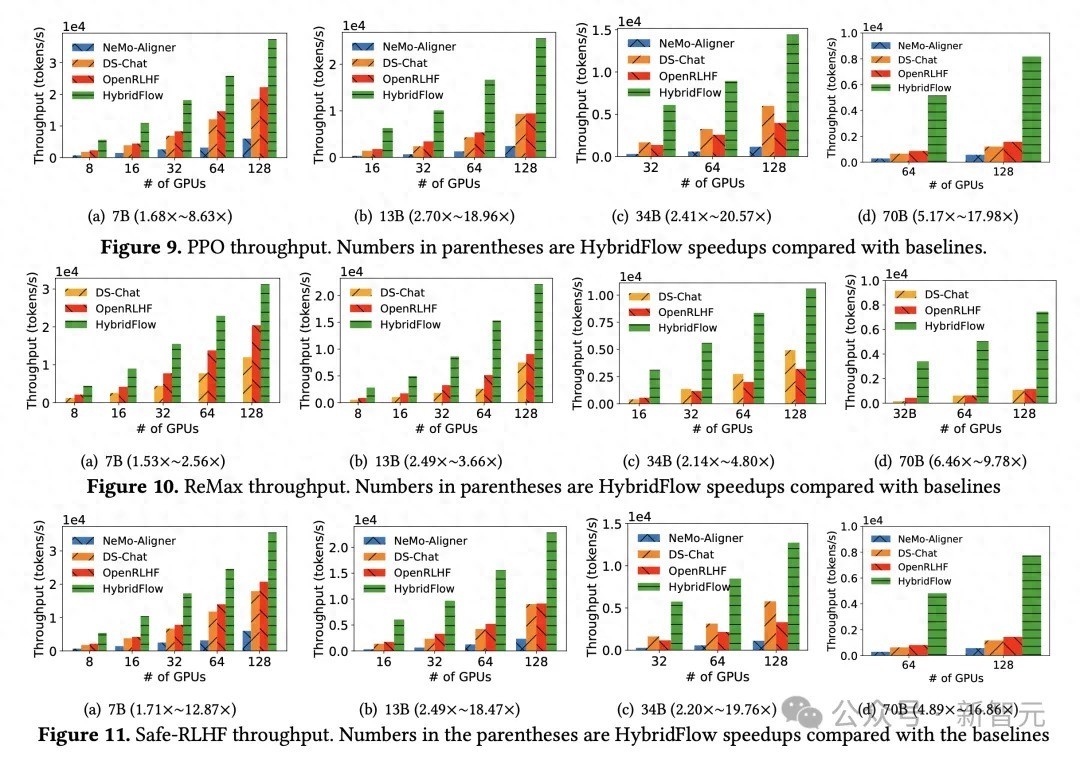
实验收尾自满,不管 PPO 、ReMax 依然 Safe-RLHF 算法,HybridFlow 在总共模子规模下平均考试朦拢量均大幅最初于其他框架,训导幅度在 1.5 倍至 20 倍之间。跟着 GPU 集群规模扩大,HybridFlow 朦拢量也得回精粹推广。这收成于其机动的模子部署,充分应用硬件资源,终了高效并行研究。同期,HybridFlow 大约援手多种散布式并行框架(Megatron-LM 、FSDP 、vLLM ),安闲不同模子规模的研究需求。
跟着 o1 模子出身,大模子 Reasoning 身手和 RL 愈发受到业界护理。豆包大模子团队默示,将延续围绕联系场景进行探索和实验。当今,HybridFlow 磋议论文已入选学术顶会 EuroSys 2025,代码也已对外开源。
HybridFlow开源聚拢:https://github.com/volcengine/veRL开云(中国)开云kaiyun·官方网站
